Whisperでの音声認識について
DisNOTEは、音声認識に複数の音声認識エンジンを使用しています。詳しくはこちらを参照してください。その中のWhisperを使用するための設定方法を説明します。
使い方
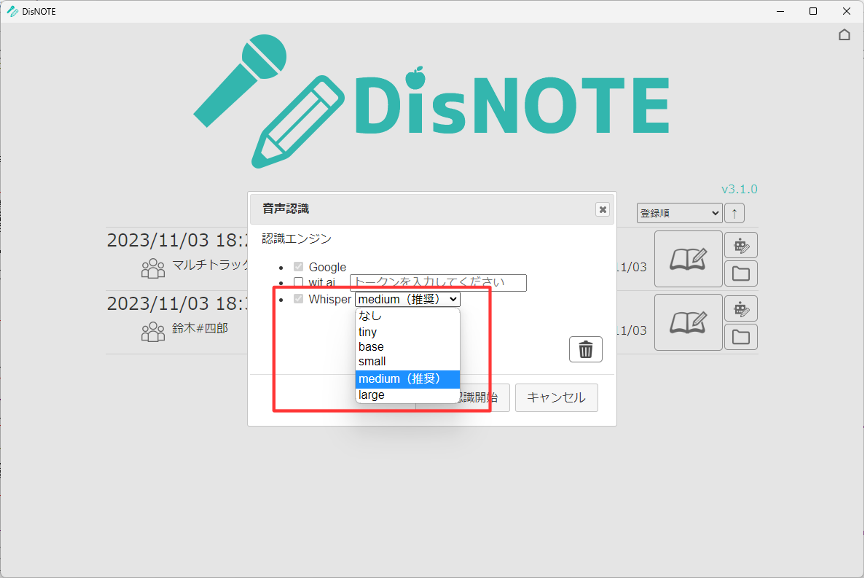
音声認識の設定画面で、Whisperの欄で使いたいモデルを選択してください。
「なし」だとWhisperでの認識を行いません。
下にいくほど認識精度が上がり、処理時間が長くなります。
また、他の音声認識エンジンと異なり、認識中はCPUを全力で使用する上に認識時間も長いので注意してください。
モデルについて
DisNOTE作者の主観ですが、tiny~smallだとGoogle Cloud Speech APIより精度が悪いです。使うのであればmediumがオススメです。| モデル | モデルデータサイズ(※1) | 認識精度 | 認識時間(※2) | 備考 |
|---|---|---|---|---|
| tiny | 70MB | 悪い ↑ ↓ 良い | 短い ↑ ↓ 長い | |
| base | 140MB | |||
| small | 470MB | |||
| medium | 1.5GB | ※オススメ | ||
| large | 3.0GB |
※2 認識速度はお使いのPCの性能に左右されます。
あとは、通常と同じようにDisNOTEを使ってください。Whisperでの認識結果が表示されるようになります。
なお、初めてWhisperを使うときは上記のモデルデータをダウンロードするので非常に時間がかかります。時間に余裕のある時にお使いください。
余談
本来WhisperはGPUを用いて高速に認識をするというライブラリなのですが、DisNOTEでは諸々の事情でGPUの代わりにCPUを用いています(遅いのはそのため)。DisNOTE.batを使う方向け
DisNOTE.batと同じフォルダにあるDisNOTE.iniというファイルを、テキストエディタで開いてください。※DisNOTE.iniが存在しなかったり、whisper_modelの行が存在しなかったらDisNOTE.batをダブルクリックして実行してください。エラーになって終了しますが、DisNOTE.iniが作成されます。
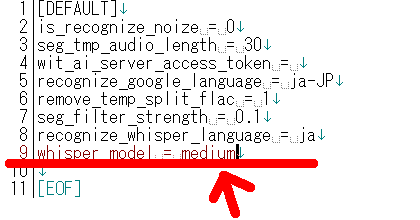
whisper_modelという項目を、モデル名に変更してください。